Harness Engineering 的介绍与编程实践
同样是用 AI 编程,有的团队已经能让 Agent 稳定改代码、跑测试、收敛结果;有的团队却还停留在“写得挺像,但一跑就炸”。差距往往出在模型外面那套工程系统,也就是让 AI 能安全干活的 Harness。
为什么会有 Harness Engineering
这两年 AI 编程工具变化很快。
最早大家更多是在“问模型”:解释代码、生成函数、补一段脚本。这个阶段最重要的是 Prompt Engineering,也就是把需求讲清楚,减少模型理解偏差。
后来大家发现,只会写提示词还不够。模型如果不知道项目目录、接口约定、历史设计和运行方式,就很容易一本正经地瞎猜。于是 Context Engineering 开始被反复提起:该给模型哪些文件、日志、文档和规则,才能让它少幻觉。
但当 AI 真的开始改文件、跑命令、修测试,问题又变了。
这时最让人头疼的,开始变成这些事:
- 破坏已有结构;
- 不按既定文档开发;
- 规避失败,假装成功;
- 顺着错误假设越修越远;
这些问题,光加一句“请谨慎操作”没什么用。你需要一套外部机制,让 AI 的行为有边界、有反馈、能收敛。这套机制,就是 Harness。
一个很好记的公式是:
Agent = Model + Harness
模型负责推理和生成,Harness 负责环境、工具、约束、状态和反馈。没有 Harness,模型更像一个会说话的大脑;有了 Harness,它才更像一个能在工程环境里干活的代理。
OpenAI 在 2026-02-11 发布的官方文章里,对这套“模型之外的工程系统”有一套比较完整的展开,本文很多整理也受它影响。
Harness 到底在管什么

可以把Harness 理解成"控制与治理层", 通俗来说就是: “护栏” + “工具链” + “运行框架”。
别把它理解成某个单独工具,也别理解成一个提示词模板。更准确地说,它是一层围着模型搭起来的工程控制系统。
落到 AI 编程场景,Harness 一般要把几件事管起来:
- 上下文管理:让代理知道项目结构、任务目标、相关文件和编码约束;
- 工具接口:让它能读文件、搜代码、跑测试、打补丁,少靠猜;
- 执行沙盒:让命令运行在受限环境里,出错也别伤到真实环境;
- 规则约束:用架构规则, skills, Hooks限制越界动作;
- 验证循环:把测试失败、构建报错、审查意见重新喂回去,让它继续修;
- 人工闸门:删文件、改生产配置、发版部署这类动作,必须有人点头。
所以我现在更倾向于把 Harness Engineering 看成一件工程活。它要解决的是环境问题:就算模型犯错,错误也尽量落在可控范围内。即:用流程与规范来约束模型。
它和 Prompt、Context 的关系
这三者可以按顺序叠起来看。
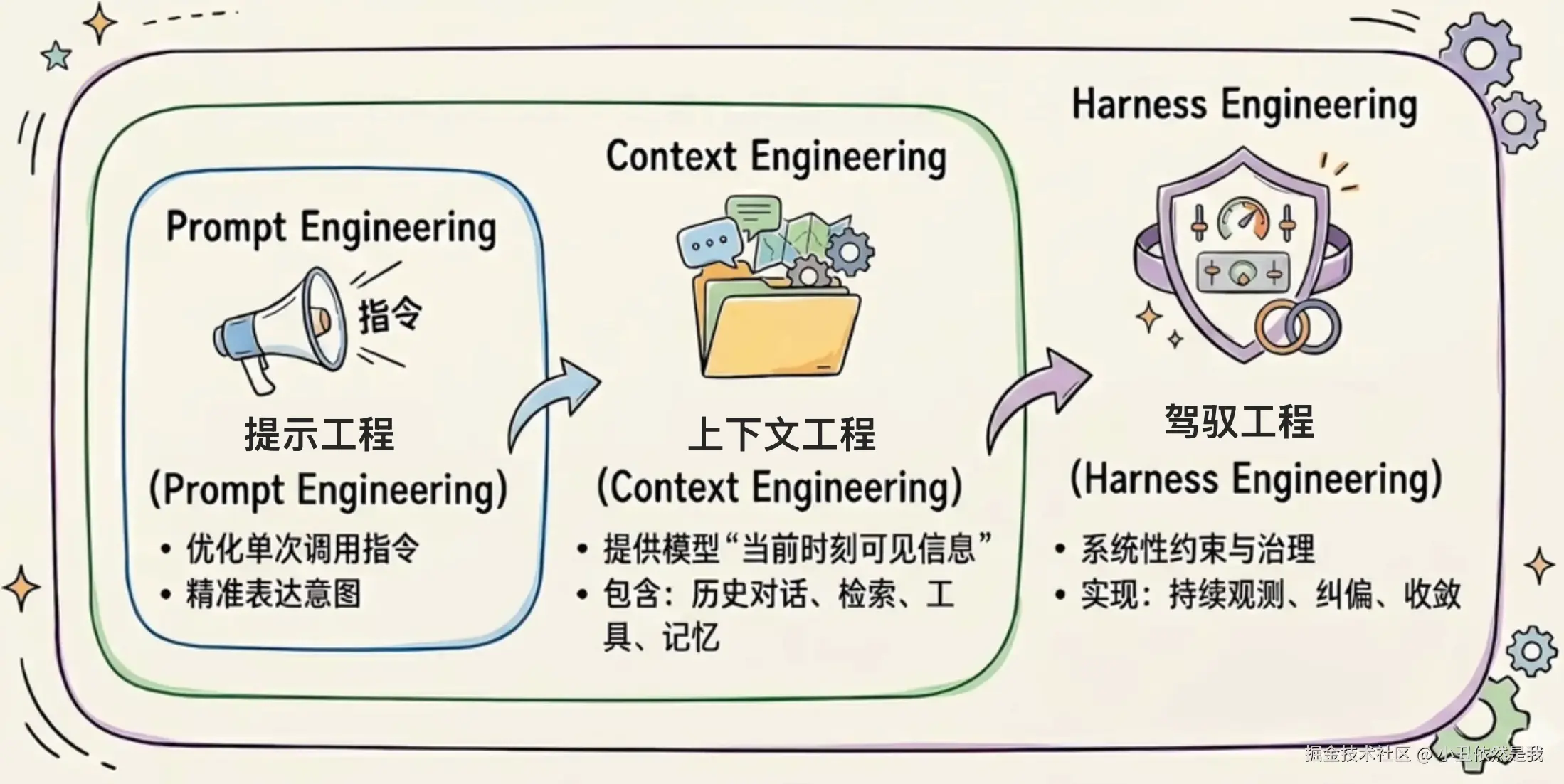
| 阶段 | 主要问题 | 关注点 | 常见手段 |
|---|---|---|---|
| Prompt Engineering | 任务没说清 | 怎么表达 | 角色、步骤、示例、输出格式 |
| Context Engineering | 模型不知道事实 | 给什么信息 | 检索文件、注入文档、压缩上下文 |
| Harness Engineering | 行为不可控 | 怎么执行和验收 | 沙盒、工具、验证、审批 |
Prompt 做得好,模型更容易听懂。
Context 给得对,模型更不容易瞎编。
Harness 搭得稳,模型就算一开始想偏了,也不会一路狂奔到把仓库搞坏。
换句话说,前两者主要解决“想清楚”,Harness 主要解决“做稳”。
如果把视角再往外拉一点,Thoughtworks 近一期 Technology Radar 里也把 Context engineering、Agent Skills、Sandboxed execution for coding agents、Feedback sensors for coding agents 拆成了独立条目。这个信号很明确:AI 编程的工程化,已经开始从零散技巧,变成可以复用的方法论和基础设施。
一个好用的 Harness 有哪几层
如果把 Harness 拆开看,我觉得至少有五层:项目地图、能力扩展层、沙盒层、验证层和收敛层。
用图来理解,会更直观一点:
这张图没有把所有细节都画全,主要想表达一点:Harness 要靠多层配合,让 Agent 一步步靠近可交付结果。
Harness工程在编程领域的实践
前置技巧
模型的能力是第一位,模型能力跟不上,harness再多也是徒劳。
定义完成的标准。只有量化的标准,才有确定的验证流程。
善用subagent,和会话管理。保持上下文的纯粹性。
利用workflow定义标准的SOP。
一开始没必要先搭很重的平台。一个最小可用的 Harness,通常可以项目地图开始切入。
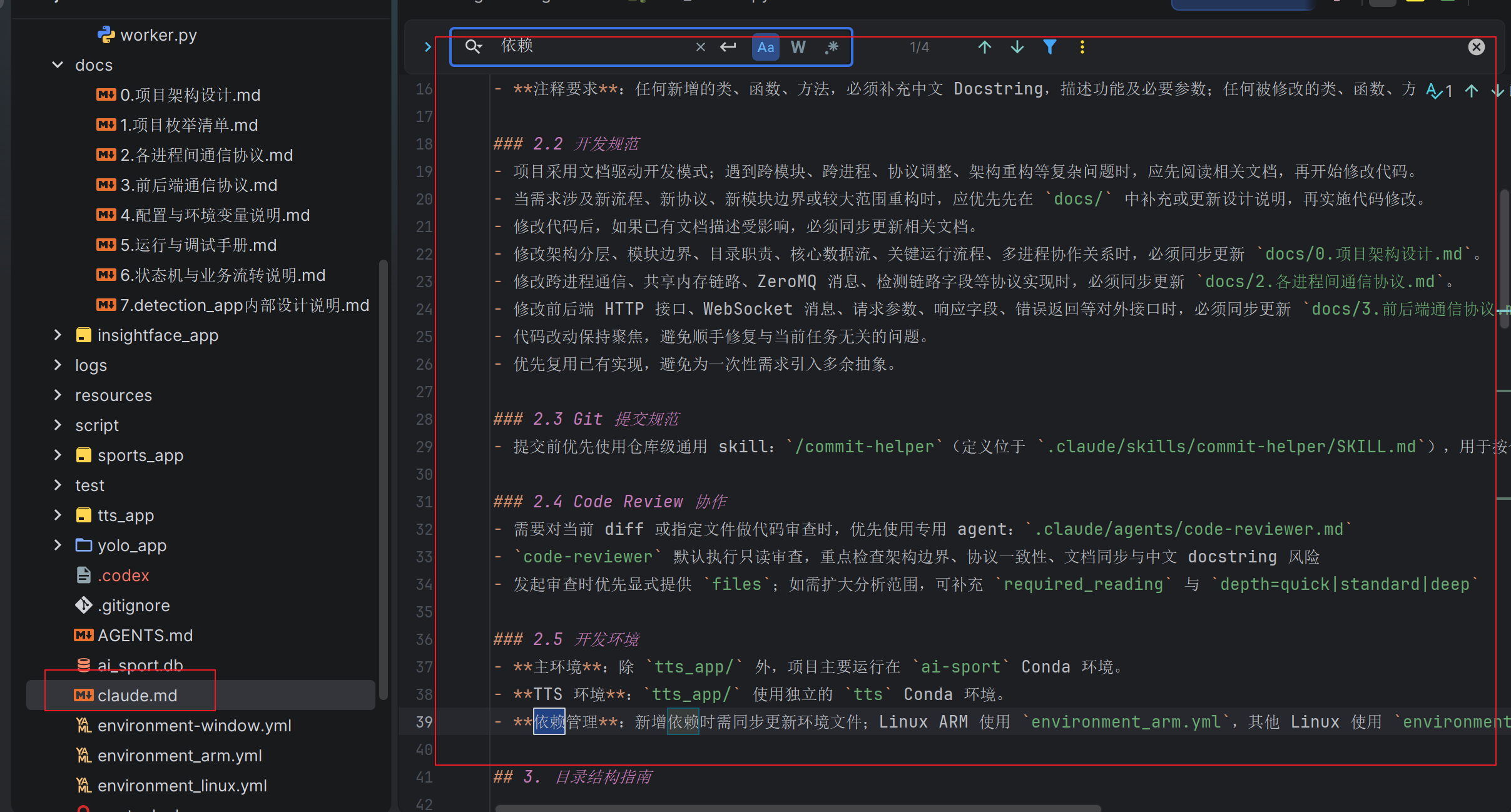
项目地图
每当 AI 进入一个项目,它对项目的了解是一篇白纸,项目地图是使用AI编程必须要做的最重要的工作。现代的agent都有init命令,不同的coding agent生成的项目地图各不相同。但是名字不重要,AGENTS.md、CLAUDE.md、团队手册都行。
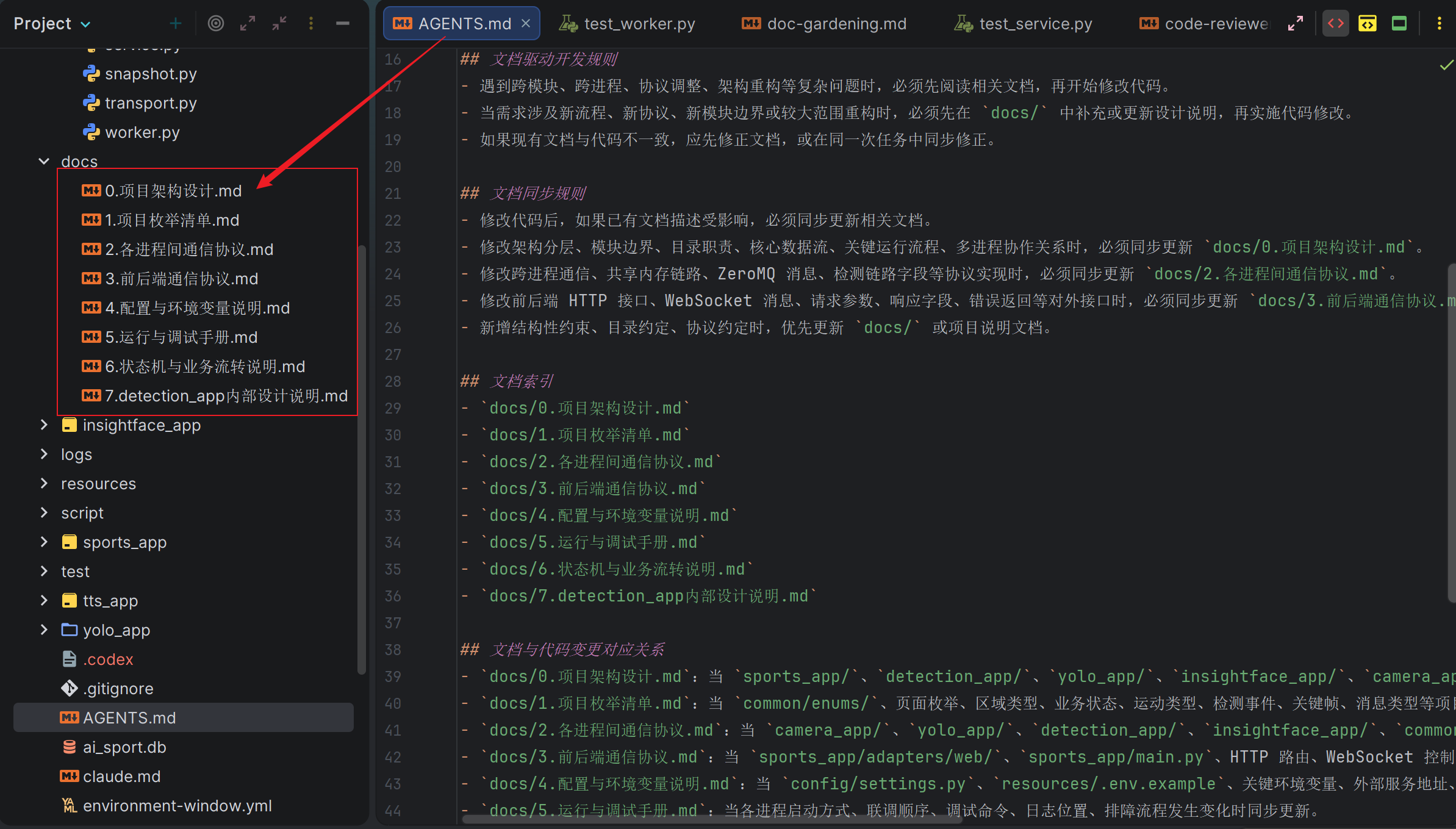
关键是需要把以下几点讲明白:
- 是什么:项目是什么技术栈?使用什么样的运行环境?架构设计和依赖方向是什么?
- 在哪里:源码、文档、测试、配置分别在哪里?常用构建和验证命令是什么?
- 禁止项:哪些目录不能手动改? 常见坑和禁止模式是什么?
技巧1: 不要把项目地图塞在一个全局地图文件中,而是提供一个清晰的入口和索引目录,让Agent按需加载,这样更省上下文,也更不容易漏重点。(此技巧跟skills的渐进式披露有异曲同工之处)
能力扩展层
模型本身不会真的“看见”仓库,它只能通过工具接触代码。
但真正落地时,这一层不只是孤零零的几个工具接口,也包括把这些能力组织起来的扩展机制。
它可以表现为命令行、MCP、Skills,也可以进一步长成agent、hooks这类运行时扩展。

沙盒层
沙盒层的作用,说白了就是先把 Agent 的活动范围圈起来。为代理执行提供更安全的环境,同时减少了对持续权限提示的需求。
它通常会限制可读写目录、网络访问、系统命令和敏感操作。
现在的大部分的主流Coding Agent都会默认创建一个沙盒。

人工闸门
沙盒解决的是“默认别乱动”,人工闸门解决的是“碰到高风险动作时,不要让 Agent 自己继续往下做”。
这两者看起来有点像,实际上分工不一样。
沙盒更像系统层面的硬限制:哪些目录能写,哪些命令能跑,网络能不能开,先由环境卡住。
人工闸门则是把最终判断权留给人。因为有些动作,不是技术上不能做,而是它的后果需要有人来承担。
一个实用原则是:越接近“真实世界副作用”,越不该全自动放行。
所以人工闸门并不是为了处处打断 Agent,而是只在高风险节点上插一手。平时让它自己读代码、改代码、跑测试;一旦要越过成本高、风险高、不可逆的边界,就先停下来,给人一个确认机会。
验证层
AI 写代码最麻烦的地方,往往不在语法。
真正难受的是:它写出来的东西乍一看像那么回事,跑起来又露馅。
所以 Harness 里必须有验证回路,不能让代理靠一句“我已经改好了”就结束任务。常见验证信号包括:
- 语法检查:格式化检查,依赖导入试运行;
- 自动化测试:单元测试,集成测试,端到端测试;
- 构建结果:运行产物,日志等;
这些检查不一定一次全上,可以分层跑。越便宜、越快的越该前置;越重的越适合放到 CI 或人工验收阶段。
更关键的是,测试失败之后,代理还能不能拿着错误信息继续修。
如果它看到报错就停,测试只是拦截器;如果它能进入“修改 -> 验证 -> 读错误 -> 再修改”的循环,Agent才能形成流程闭环。
收敛层
长任务里,AI 很容易出现一种情况:修 A 引入 B,修 B 又破坏 C,最后越改越偏。
所以一个好的 Harness,要同时告诉代理怎么做事、什么时候才算做完。
这个“做完”不能只听模型自己说,要看外部事实。比如:
- 预期目标已经完成;
- 相关测试通过了;
- 运行结果也与预期一致了;
FAQ
- 收敛层的产物是什么?
收敛层让Agent对整个流程进行一个收尾总结,如计划做什么任务,怎么实现的,遇到了哪些问题,通过什么方式解决的,解决是否真的成功了,相关自动化是否通过了,然后再输出一份任务总结汇报,即可代表该项任务已完成。
- 如果一直无法收敛怎么办?
遇到无法收敛的情况大致分为两类,一类是确实无解的问题,此时需要仔细梳理全流程,研究方案的可行性。第二类是,由于上下文污染导致的行动方向错误了,此时应尽早的中断回话,新开回话。

Harness工程发展的两个方向
- 内化到模型里
- 内化到Coding Agent编程工具里
一些推荐的agent/skills项目
- https://github.com/gsd-build/get-shit-done,上下文工程与规格驱动开发系统,含agent和skills
- https://github.com/obra/superpowers,给 AI 编码助手的高阶工程化技能库,靠标准化流程、TDD、子代理与规范审查,强行把 AI 编码拉到专业工程级水准。
- PUA SKILL/NOPUA SkILL, 一套PUSH AI的方法论Skill
结语
每当你发现 Agent 犯了一个错误,你就花时间设计一个解决方案,使 Agent 永远不再犯同样的错误。——Harness Engineering
AI 负责把速度拉起来,人负责守住工程确定性。
当 AI 写代码的速度已经快到人很难逐行盯完时,真正让人安心的,往往是你有没有能力把它犯过的错,持续变成下一次不会再掉进去的工程护栏。
参考资料
- OpenAI. Harness engineering: leveraging Codex in an agent-first world
https://openai.com/index/harness-engineering/ - Thoughtworks Technology Radar: Context engineering
https://www.thoughtworks.com/radar/techniques/context-engineering - Thoughtworks Technology Radar: Agent Skills
https://www.thoughtworks.com/radar/techniques/agent-skills - Thoughtworks Technology Radar: Sandboxed execution for coding agents
https://www.thoughtworks.com/radar/techniques/sandboxed-execution-for-coding-agents - Thoughtworks Technology Radar: Feedback sensors for coding agents
https://www.thoughtworks.com/radar/techniques/feedback-sensors-for-coding-agents - Harness Engineering在硅谷爆火,一文带你搞懂! https://zhuanlan.zhihu.com/p/2021716359613032366
版权声明: 本文首发于 指尖魔法屋-Harness Engineering 的介绍与编程实践(https://blog.thinkmoon.cn/post/993_harness-engineering%E7%9A%84%E4%BB%8B%E7%BB%8D%E4%B8%8E%E5%AE%9E%E8%B7%B5/) 转载或引用必须申明原指尖魔法屋来源及源地址!