OpenAI Responses API Web Search Agent Python调试 OpenAI Responses API 的 Web Search 踩坑记录本文记录一次在投资研究 Agent 中调试 OpenAI Responses API Web Search 工具的过程,重点梳理请求格式、流式 SSE 解析、工具名兼容性和结构化数据源设计。 醉月思📁 技术实践📅 2026-04-30
Python 量化使用python实现动量量化策略监控面板基于 Python 的动量轮动量化策略监控面板,使用 AkShare 获取数据,Streamlit 可视化展示并提供回测示例。 醉月思📁 技术实践📅 2025-12-22
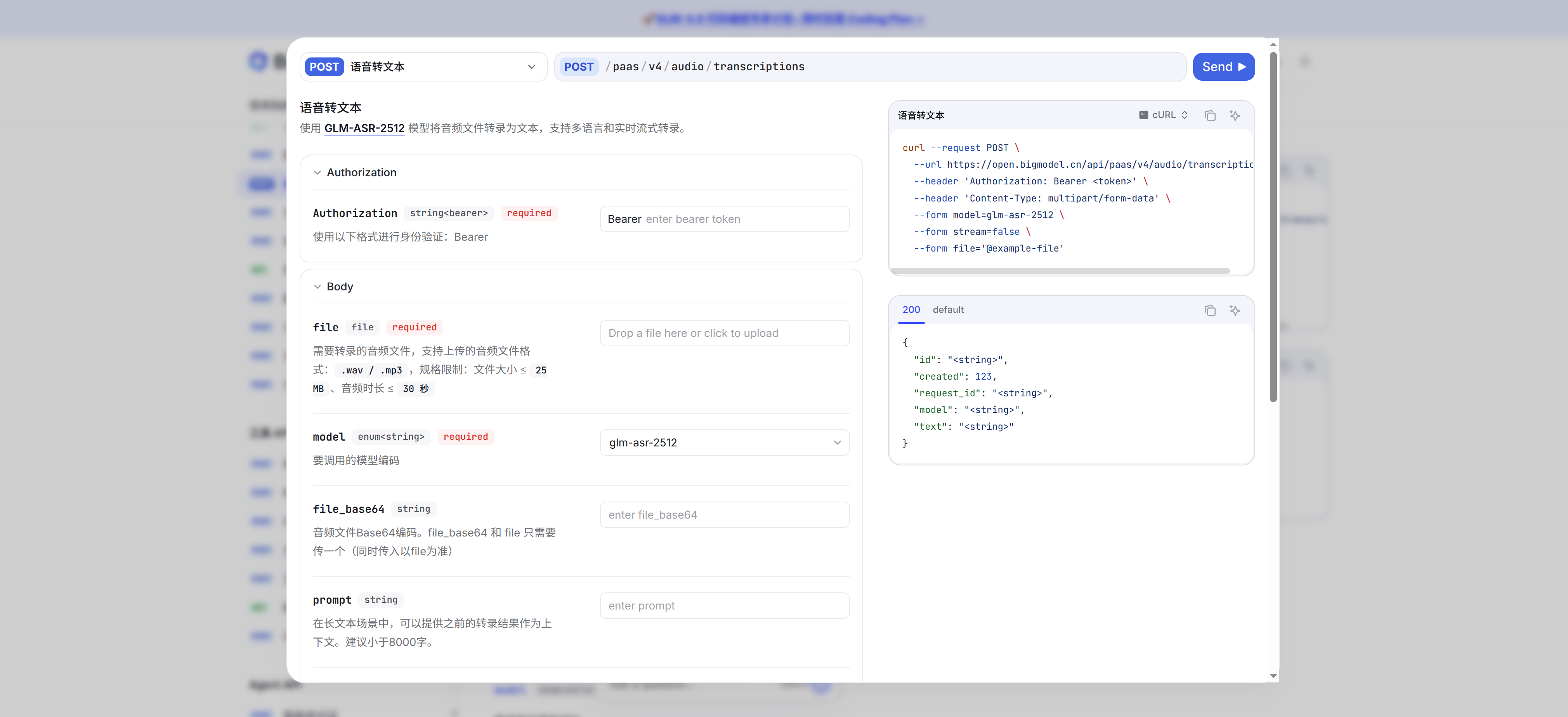
Python 语音识别使用智谱api将长语音转文本智谱AI API虽性能优异但仅支持30秒以内音频文件。本文详细介绍如何基于pyannote.audio的语音活动检测技术实现智能音频分块,通过批量API调用构建完整的长语音转文本系统,包含完整的环境配置、代码实现和部署方案。 醉月思📁 技术实践📅 2025-12-16
python typing探索 Python 的 Typing 库:增强代码健壮性本文深入探讨 Python 的 typing 库,介绍类型注解的基本用法、高级特性(如 Optional、Union、泛型)及其在提升代码健壮性、可读性和 IDE 支持方面的优势。通过实战示例,帮助开发者掌握静态类型检查,编写更安全、可维护的 Python 代码。 醉月思📁 学习笔记📅 2025-09-29
python pip venv virtualenvPython 虚拟环境与包管理完整指南本文详细介绍了在 Windows 系统中配置 pip 清华源、创建虚拟环境(venv 和 virtualenv)、管理依赖包等内容。通过本指南,开发者可以有效隔离项目依赖,避免版本冲突,提升 Python 开发效率。 醉月思📁 教程分享📅 2024-06-07
OpenWrt Python路由器openwrt安装python本文详细介绍了如何在OpenWrt路由器上挂载U盘,并将Python3及其依赖包安装到U盘中。通过配置opkg安装目录和PATH环境变量,解决了路由器存储空间不足的问题,同时避免了因U盘掉线导致系统无法启动的风险,适合折腾路由器的用户参考。 醉月思📁 教程分享📅 2023-12-25
django pythonDjango启航篇本文详细介绍了Django框架的入门安装与配置流程,涵盖pip3的安装、Django的部署、环境验证以及如何创建和运行第一个Django项目。内容简明扼要,适合Python初学者快速上手Web开发。 醉月思📁 教程分享📅 2020-06-30
leetcode python【leetcode】5. Longest Palindromic Substring最长回文子串本文详细介绍了LeetCode第5题“最长回文子串”的解法。首先讲解了中心拓展算法的基本思路和Python实现,随后深入剖析了线性时间复杂度的马拉车算法,并提供了完整的代码示例及运行成果展示。 醉月思📁 学习笔记📅 2020-02-06
algorithm pythonmanacher(马拉车)算法讲解本文深入讲解了 Manacher(马拉车)算法,这是一种用于寻找字符串中最长回文子串的高效线性算法。文章详细剖析了算法的核心思想、辅助数组的含义以及边界条件的处理,并提供了 Python 代码示例,帮助读者快速理解并解决 LeetCode 中的回文串问题。 醉月思📁 学习笔记📅 2020-01-31
leetcode python【leetcode】4. Median of Two Sorted Arrays寻找两个有序数组的中位数本文记录了 LeetCode 第 4 题“寻找两个有序数组的中位数”的初次解题思路。作者通过合并数组并排序的方式实现了基本功能,但随后分析了该解法的时间复杂度不足,为后续优化奠定基础。 醉月思📁 学习笔记📅 2020-01-22